



# Plans
# Overview
Plans capture the individual steps of operational tasks. A plan organizes these tasks into phases and steps. Each step references the tasks to run for this step. By organizing steps into phases, complex behavior of services can be captured.
Plans and phases have a strategy. The strategy indicates if phases and steps should run in parallel or in serial.
...
tasks:
- name: deploy-master
kind: Apply
spec:
resources:
- master-service.yaml
- master.yaml
- name: deploy-agent
kind: Apply
spec:
resources:
- agent-service.yaml
- agent.yaml
plans:
deploy:
strategy: parallel
phases:
- name: deploy-master
strategy: serial
steps:
- name: deploy-master
tasks:
- deploy-master
- name: deploy-agent
strategy: serial
steps:
- name: deploy-agent
tasks:
- deploy-agent
The KUDO controller deploys the plans of an operator. Only a single plan can be in active deployment at a time. KUDO has different approaches to decide which plan to deploy.
# Deploy and update plans
By default, KUDO will start the deploy plan if no other plan has been deployed yet. In case of an instance update, KUDO will start a upgrade or update plan if it exists. If none of these plans exist, KUDO will start the deploy plan.
In the example below, the deploy plan creates a service defined in service.yaml. In case of an update, the service's cache needs to be updated. The update-cache.yaml provides the necessary resources to do that and thus is part of the update plan.
...
tasks:
- name: app
kind: Apply
spec:
resources:
- service.yaml
- name: update
kind: Apply
spec:
resources:
- service.yaml
- update-cache.yaml
plans:
deploy:
strategy: serial
phases:
- name: deploy-service
strategy: serial
steps:
- name: deploy
tasks:
- app
update:
strategy: serial
phases:
- name: update-service
strategy: serial
steps:
- name: update
tasks:
- update
# Cleanup plans
If an optional cleanup plan is part of an operator, this plan will run as part of the deletion of an Instance. Once this plan completes or fails, the instance will be deleted.
This plan (if exists) will be triggered by the KUDO manager automatically once the Instance is being deleted. Trying to trigger it during the normal life-cycle of the Instance will lead to an error. Furthermore, it should be expected that the steps of this plan could fail. E.g., users may want to delete an instance because its deploy plan is stuck. In that case resources that the cleanup plan tries to remove might not exist on the cluster. The cleanup plan will start even if other plans are in progress.
...
tasks:
- name: database
kind: Apply
spec:
resources:
- database.yaml
- name: cleanup
kind: Apply
spec:
resources:
- cleanup-job.yaml
spec:
plans:
deploy:
strategy: serial
phases:
- name: deploy-database
strategy: serial
steps:
- name: deploy
tasks:
- database
cleanup:
strategy: serial
phases:
- name: cleanup-databse
strategy: serial
steps:
- name: cleanup
tasks:
- cleanup
Note, that it is not necessary to remove the database.yaml as all resources belonging to the Instance will be removed automatically when the instance is deleted. However, complex application sometimes create state which cannot be captured by Kubernetes resources. As this state may have to be removed when removing the respective operator, a cleanup plan can take care of that. The example above bundles that tasks needed to remove this state in a Job provided by the cleanup-job.yaml. In general a cleanup plan is like any other plan except that it is being called before the Instance is deleted.
The cleanup plan is implemented using finalizers (opens new window). The instance's metadata.finalizers contains the value "kudo.dev.instance.cleanup" while the cleanup plan is in progress.
# Parameter triggers
Parameters can have optional triggers. A trigger references a plan that will run if the parameter is updated.
The operations required to update a running application can vary depending on which parameter is
being updated. For instance updating the BROKER_COUNT, may require a simple update of the deployment, whereas
updating the APPLICATION_MEMORY may require rolling out a new version via a canary or blue/green deployment.
...
parameters:
- name: REPLICAS
trigger: deploy
- name: APPLICATION_MEMORY
trigger: canary
# Executing Plans
In general, KUDO manager will automatically execute a plan when the corresponding parameter changes. However, sometimes this is not enough. Sometimes you need to trigger a plan manually, e.g. to create a periodic backup, or restore data in case of data corruption. Such plans typically do not need a corresponding parameter. KUDO v0.11.0 (opens new window) introduced new feature: manual plan execution. In a nutshell, you can now:
$ kubectl kudo plan trigger --name deploy --instance my-instance
which will trigger the deploy plan and execute it on my-instance. While this looks relatively easy on the surface, the devil is in detail, so let's take a closer look.
# Plan Life Cycle
Having the ability to trigger multiple plans on demand raises the question: what happens if two plans run concurrently? The answer is: it depends. Should two plans be completely independent of each other (e.g. deploy deploys the services and monitor deploys the monitoring pods) both can be executed in parallel. But if two plans in question are backup and restore or deploy and migrate? Some plans are incompatible with others. A few may not even be reentrant. While it is probably ok to restart a running deploy plan, a restore plan might not be reentrant because of possible data corruption.
We're planning to explore the realm of plan compatibility further in the future. Annotating plan affinity and anti-affinity, reentrant vs non-reentrant plans, plan cancellation and transient plan parameters are some of the topics we're examining. All contributions and feedback are highly welcome.
Having all this in mind how can we ensure correct plan execution? Meet Kubernetes admission controllers.
# Admission Controllers
In a nutshell, Kubernetes admission controllers are plugins that govern and enforce how the cluster is used. They can be thought of as a gatekeeper that intercepts (authenticated) API requests and may change the request object or deny the request altogether. Kubernetes already comes with a bunch of these pre-installed (opens new window) which govern everything from user authorization to the namespace life cycle.
KUDO manager employs an Instance admission controller that governs changes to Instances, making sure that plans do not interfere. Schematically this looks like the following:
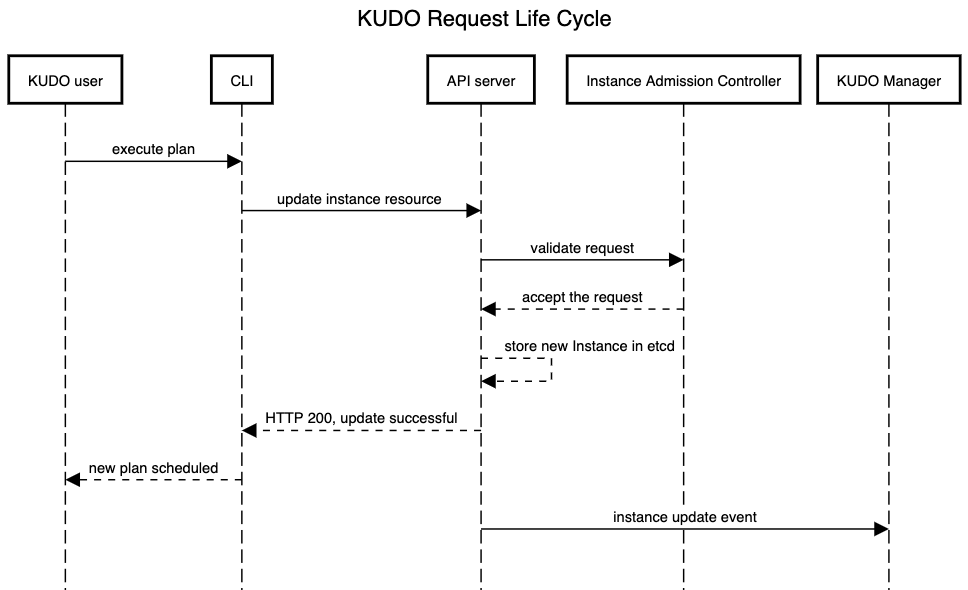
Instance admission controller governs any update to the Instance either through manual plan execution or Instance parameter updates. The general rule of thumb is the following: all plans should be terminal (either successfully with status COMPLETE or unsuccessfully with FATAL_ERROR) before a new plan is allowed to start. A singular plan can be restarted so we assume all plans to be reentrant at least for now. While this might not be true for all plans, we think that it covers the 80/20 case e.g. when a deploy plan is stuck and must be restarted with less memory per node. In case a request is rejected, the Instance controller returns an error explaining why exactly the update was denied.
The admission controller would also reject parameter updates that would trigger multiple distinct plans. There are a few exceptions too: for example, a cleanup plan is special and is executed when an Instance is deleted. cleanup can not be triggered manually and is allowed to override any existing plan (since the Instance is being deleted anyway).
As of KUDO v0.11.0, the Instance admission controller is optional though we're planing to make it mandatory in the near future. See kudo init documentation for more details.